







Поисковая ИТ-система, основанная на когнитивном анализе данных
↓35%
Время на поиск информации
сократилось на 35%

«Лучшие 10 ИТ-проектов для нефтегазовой отрасли» ComNews
Naumen Enterprise Search — поисковая система для решения задач в области корпоративного поиска информации. Интеллектуальная система поиска с применением машинного обучения и средств обработки естественного языка (Natural Language Processing, NLP) способна обрабатывать большие массивы информации и делать накопленную информацию доступной для сотрудников организации.
Системой Naumen Enterprise Search смогут пользоваться все сотрудники компании. В первую очередь, система поиска поможет снизить трудозатраты у специалистов, ежедневно работающих с документами в производственных подразделениях, финансовых, юридических и кадровых службах, секретарей и делопроизводителей.
Возможности системы позволяют вести поиск не только среди электронных документов,
но и в архивах видео и изображений*
*— при наличии у файлов учетных карточек с описанием, корпоративных системах обработки информации:
CRM, ERP, электронная почта,
Инженерные и производственные проекты
Система умного поиска поможет:
Организационное развитие
С помощью системы умного поиска вы можете оперативнее и с меньшими затратами:
Управление клиентским опытом
Система умного поиска поможет оптимизировать клиентский сервис и улучшить опыт клиентов:
Развитие человеческого капитала
Система умного поиска способна помочь компании:
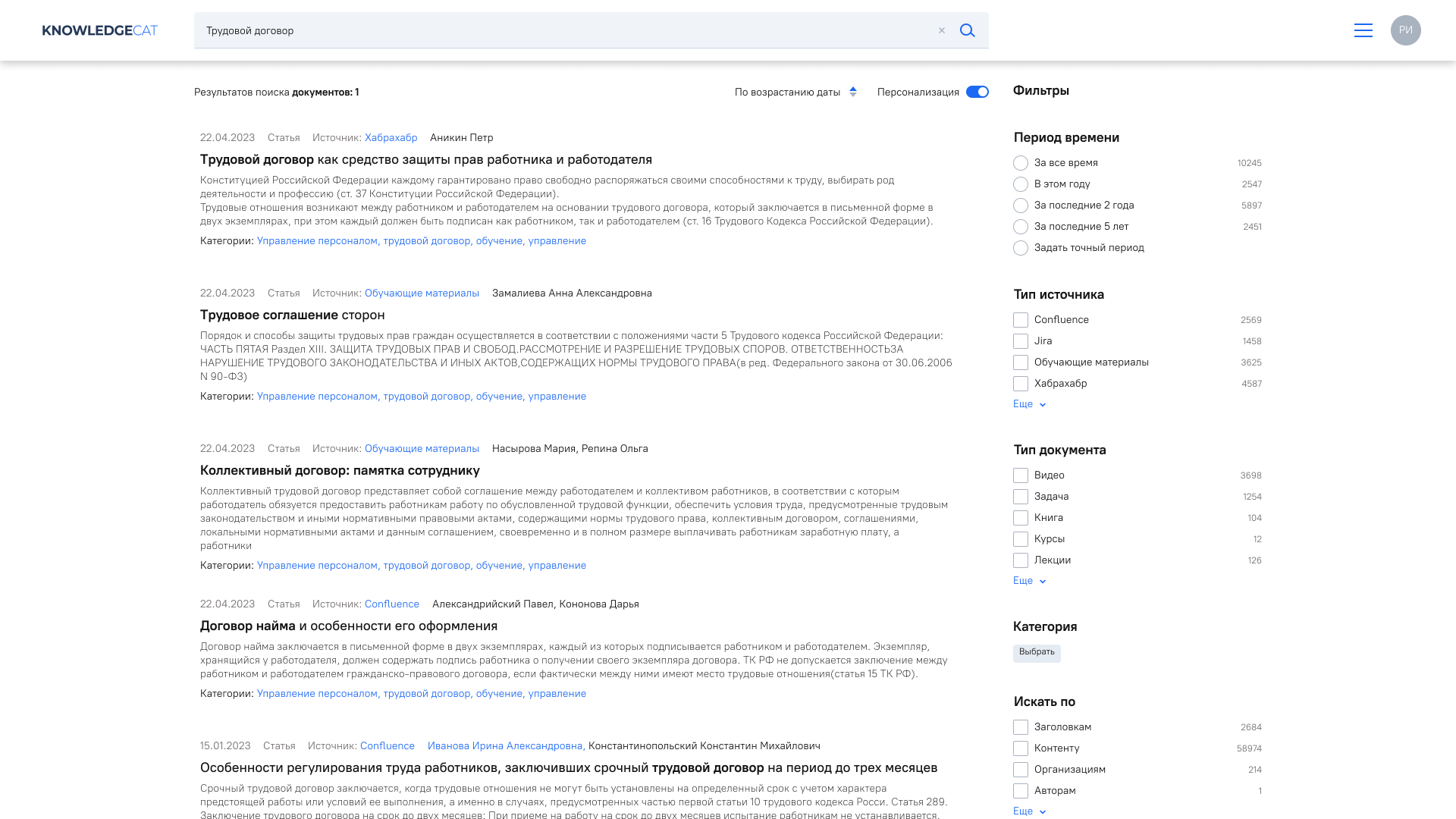
Динамическое построение фильтров с учетом результатов поиска и прав пользователя
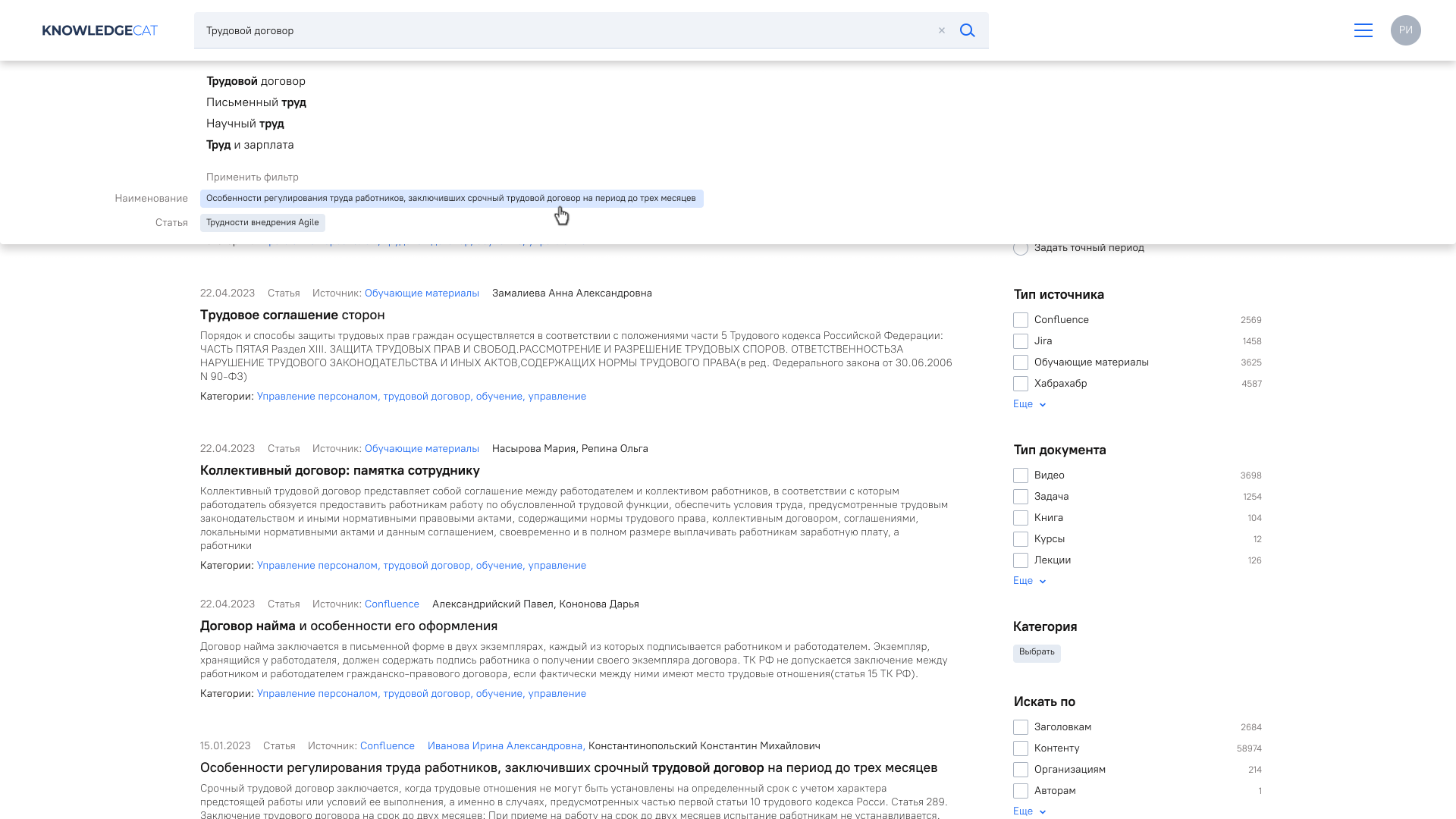
При вводе поискового запроса пользователю предлагаются возможные варианты его завершения – слово, словосочетание или заголовок документа.
Автоматическая корректировка орфографии и опечаток в поисковом запросе.
Результаты поиска зависят от знаний об отдельном пользователе – должность, подразделение, история действий в системе, другие корпоративные характеристики
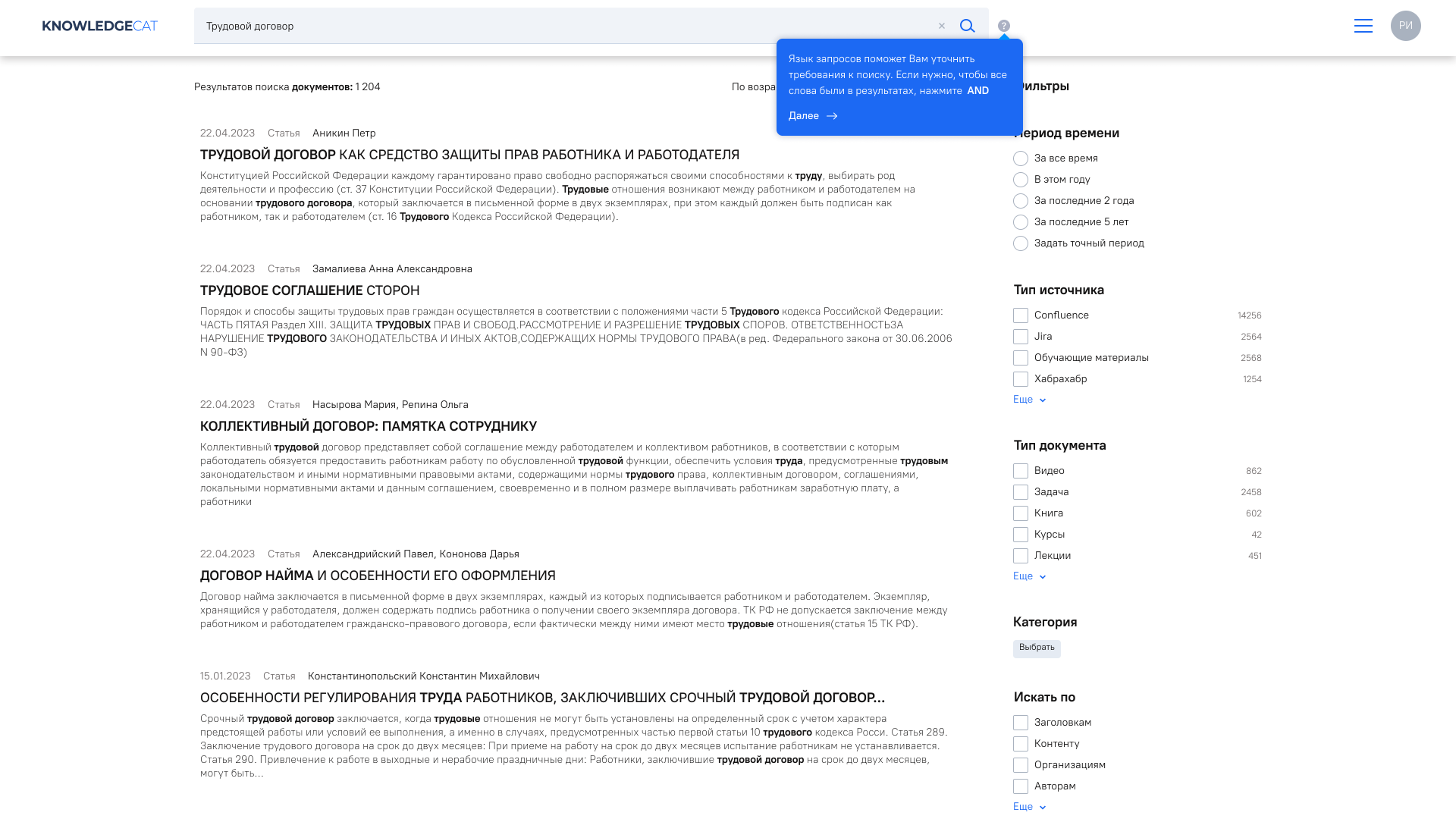
Пользователь может использовать логические операторы (И, ИЛИ, НЕ и др.) для более точного формулирования поискового запроса
Поисковая ИТ-система, основанная на когнитивном анализе данных
Время на поиск информации
сократилось на 35%
«Лучшие 10 ИТ-проектов для нефтегазовой отрасли» ComNews



Группировка документов по одной тематике
Автоматическое построение каталога с помощью тематической кластеризации поможет сотрудникам изучать незнакомую предметную область, накопленные в компании знания и находить артефакты, которые есть по теме в рамках
Выделение из контента атрибутов
для дополнительной фильтрации
Для больших массивов неструктурированной однотипной информации (хранилища с договорными или проектными документами) выделение из контента именованных сущностей позволит ускорить поиск данных за счет:
Поддержка онтологий
В специализированных областях знаний применение онтологий позволяет дать более точное описание предметной области и использовать эти сведения для обогащения и уточнения поисковой выдачи по запросам, содержащим специализированную лексику.
Краулер внешних систем


